I now want to describe some of the basic data structure we used for our library.
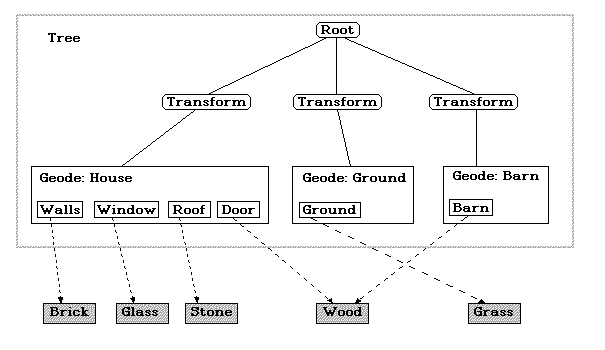
We use a tree to represent the scene we want to render. The tree structure we use is very similar to the trees used by openInventor or Performer[2].
Basically there are two types of nodes in our tree:
- transformation nodes
- object nodes
Transformation nodes basically are good old 4x4 transformation matrixes, describing the movement of the object nodes 'below' the transformation nodes.
Object nodes are some sort of movable objects - usually geometric objects, cameras, lights and so on.
When we want to render the scene, we initialize a transformation matrix with the identity matrix. Then we recursively traverse the tree. Each time we meet a transformation matrix we combine this transformation with our current transformation matrix (simple matrix multiplication).
Each object node we meet, we transform with the current transformation matrix. Whenever we return from a sub-tree we have to restore the original matrix. This can easily be achieved by the use of a matrix stack.
Because transformation matrixes are combined while we go down in our tree, we have a very natural way to describe geometric dependencies.
Lets look at an example scene with a light and a car with its four wheels:
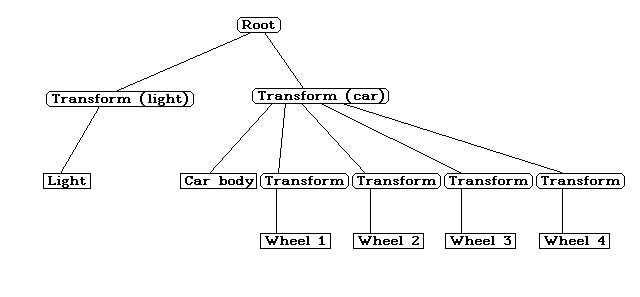
Fig. 1
: the scene treeIn the scene described in Fig. 1 there's a transformation matrix for the light and for the car. This means that the light and the car can move independently from each other.
The car transform has five 'children': The car body, and 4 transforms, each for one wheel of the car.
Because the wheel transforms are combined with the car transforms, the wheels can have their individual movement (spin, etc.) and still also have the same overall movement of the car. So if the car moves to the left, all four wheels do the same left movement as the car body, plus their individual movement.
Summary: The whole scene is kept in a tree. There are two basic nodes: 'transforms' and 'objects'. 'transforms' are combined as we traverse the tree and are applied to 'objects' below them in the tree. 'objects' can be anything from lights to cameras, to geometric data.