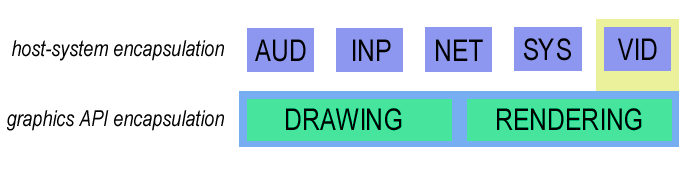
Figure 1: Parsec subsystem structure
Institute of Computer Graphics
Vienna University of Technology
Vienna / Austria
Keywords: graphics
APIs, OpenGL, Glide, entertainment software, computer games, real-time
graphics, portability.
VID_DEFS.H:#ifdef DBIND_VID
// make use of jump-table transparent
#define VIDs_InitDisplay (*vid_subsys_jtab.InitDisplay)
#else
// ordinary prototype
void VIDs_InitDisplay();
#endif
VID_CALLER.C:
#include "vid_defs.h"
// use VID function
VIDs_InitDisplay();
Thus, the caller simply uses the function name without considering the type of binding at all. The next figure shows how the callee declares a function it wants to implement. Note that in the case of dynamic binding the actual function name that will go into the object module has to be unique among subsystems - hence the redefinition of the function name. The only module knowing about these names is the one setting the correct addresses in the jump-table.
VW_INITG.H:#ifdef DBIND_VID
// undefine because we are callee (implementor)
#undef VIDs_InitDisplay
// redefine name to avoid nameclash with other implementations
#define VIDs_InitDisplay VIDs_GLIDE_InitDisplay
#endif
VW_INITG.C:
// subsystem header
#include "vid_defs.h"// local module header
#include "vw_initg.h"// actual name may have been redefined transparently
void VIDs_InitDisplay()
{
// implementation for this subsystem
}
In this way, there will be functions containing _GLIDE_, _OPENGL_, etc.
in their function names. However, these are never used directly, apart
from the jump-table management module. This system is very simple and transparent
to both caller and callee - and therefore very easy to use. The only overhead
involved is that all calls to exported subsystem functions will be indirect
instead of direct. This has proved to impact performance nearly not at
all, also due to the fact that all subsystem functions are designed in
a way that their execution takes significantly longer than the time the
call and return themselves take. Still, dynamic binding can be disabled
by changing a single #define if the overhead is felt to be unnecessary
and there is only one implementation for each subsystem.
struct vid_subsys_jtab_s {// BUFF GROUP
void (* ClearRenderBuffer )();
void (* CommitRenderBuffer )();// INIT GROUP
void (* InitDisplay )();
void (* RestoreDisplay )();
void (* InitFrameBufferAPI )();// SUPP GROUP
int (* SetGammaCorrection )( float gamma );};
struct d_subsys_jtab_s {// BLIT GROUP
int (* ReadBuffRegion )( int buffid, ... );// BMAP GROUP
void (* PutBitmap )( char *bitmap, ... );
void (* PutTrBitmap )( char *bitmap, ... );// ITER GROUP
void (* DrawIterTriangle3 )( IterTriangle3 *ittri );
void (* DrawIterTriStrip3 )( IterTriStrip3 *itstrip );
};
struct r_subsys_jtab_s {// OBJ GROUP
void (* RenderObject )( GenObject *objectp );
void (* DrawWorld )( const Camera camera );// PART GROUP
int (* DrawParticleCluster )( pcluster_s *cluster );
void (* DrawParticles )();// SFX GROUP
void (* DrawLensFlare )();
void (* DrawPanorama )();
};
enum itertype_t {iter_constrgb, // constant (rgb) attributes
iter_constrgba, // constant (rgba) attributes
iter_rgb, // iterate (rgb) attributes
iter_rgba, // iterate (rgba) attributes
iter_texonly, // apply texture without shading
iter_texconsta, // modulate texture with constant (a)
iter_texconstrgb, // modulate texture with constant (rgb)
iter_texconstrgba, // modulate texture with constant (rgba)
iter_texa, // modulate texture with iterated (a)
iter_texrgb, // modulate texture with iterated (rgb)
iter_texrgba, // modulate texture with iterated (rgba)
iter_constrgbtexa, // constant (rgb) with alpha-only texture
iter_constrgbatexa, // constant (rgba) with alpha-only texture
iter_rgbtexa, // iterated (rgb) with alpha-only texture
iter_rgbatexa, // iterated (rgba) with alpha-only textureiter_overwrite, // overwrite destination
iter_alphablend, // alpha blend with destination
iter_modulate, // modulate destination (multiply)
iter_specularadd, // add to destination (emissive/specular)
iter_premulblend, // blend with premultiplied alpha
};
| AMD | AMD web-site. See http://www.amd.com. |
| DirectX | DirectX and Direct3D. See http://www.microsoft.com/directx. |
| Glide | 3dfx Interactive Glide Rasterization Library. See http://www.3dfx.com. |
| GLsite | OpenGL web-site. See http://www.opengl.org. |
| Intel | Intel developer web-site. See http://developer.intel.com. |
| Parsec | Parsec - Fast-paced multiplayer cross-platform 3D Internet space combat. See http://www.parsec.org. |