We have tested the briefly described algorithms to establish
visibility relations on several different models of architectural
interiors. Table 1 depicts times spend by the visibility
preprocessing as well as the asset of visibility computations. The
percentage of cells classified as visible shows, that the visibility
computations significantly reduce the amount of data necessary to
process during rendering. However, efficiency of the visibility
preprocessing tends to decrease rapidly with lower density of
occluders in the environment (scene named 6supr). In the case
of sparsely occluded environments the size of visibility trees grows,
because of the combinatorial explosion of the passable portal
sequences. Now, let us provide a short discussion as a subject of
the following paragraphs.
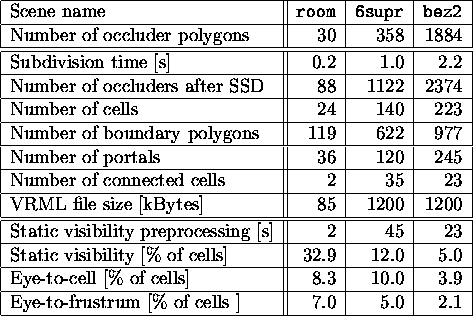
Table 1: Results of the spatial subdivision and visibility
computations. The table shows the time spend by the preprocessing as
well as the average percentage of the portion of the model classified
as visible. Measured on K5/100MHz, 32MB RAM, Linux OS.
We have showed that rendering can be significantly speeded-up using
an algorithm to determine the visible portion of the model in advance
(i.e. before actually rendering it). However, a question remains how
much work should be done as a preprocessing and what should be left
for real-time calculations. Obviously, more precise preprocessing
yields higher storage complexity for the precomputed information,
while on the other hand reduces the complexity of on-line calculations
and possibly increases their efficiency. Another question, which has
not been answered yet, is when the usage of the portal based methods
starts to be inefficient, leaving a place for the obscuration culling
to be applied.
As already mentioned, the PVS based approach is efficient for
processing densely occluded environments with cells and portals
inherited in their structure. For such types of MVEs this method gives
very good results and the preprocessed information is very close to
the actually visible portion of the model. Moreover the dynamic
queries can be performed very simply and quickly. However, if the
model is not feasible enough preprocessing based on the PVS approach
leads to enormous storage requirements. In such cases even more time
can be spend during the dynamic queries than it would be needed using
some most naive algorithm.
Obscuration culling methods are a general scheme,
since practically no assumptions about the scene structure are
required. This arises from the fact, that no search for the topology
of the model has to be performed, namely no portals and cells need to
be found. Obscuration culling methods use the ``already defined''
primitives such as polygons, to cull away the invisible portions of
the model in contrast to the determination of the potentially visible
sets induced by the transparent(!) portions of the model. Their
potential weakness is the lack of knowledge about connectivity of
primitives causing an occlusion, namely for densely occluded models
(note the contrast to cell-portal approach).
It seems that most of todays research focuses on the improvement
of the obscuration culling methods, since they are not so sensitive to
the type of model being visualized and provide more freedom in terms
of balance between preprocessing and real-time computations.
Moreover as shown in [CT96], when more calculations are left
for the real-time processing, the use of spatial and temporal
coherence can significantly reduce their complexity.
Jiri Bittner - bittner@sgi.felk.cvut.cz